电商平台供应链的业务场景非常复杂,技术中台需要支持非常复杂且不断变化的业务需求,构建了数量繁多且紧密耦合的业务链路,为技术架构的维护带来了压力。
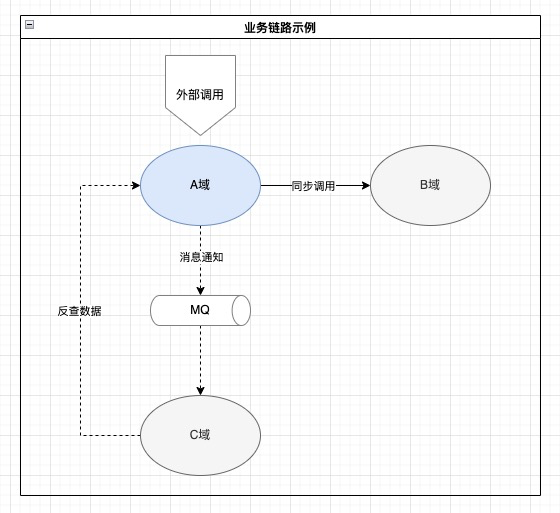
上图是一个典型的业务架构,A域是上游域,B域和C域是下游域。A域在收到外部调用请求时,首先同步调用B域的服务接口完成同步业务逻辑,然后发送消息通知到MQ。C域异步消费消息后,反向调用A域的接口查询详细信息,完成异步业务逻辑。
这种架构的问题包括:
(1) A域强依赖B域的接口,B域接口变动会导致A域调用失败,而A域无法管控B域的接口变动;
(2). C域收到消息后需要反查A域的接口,对A域形成了双重依赖,A域接口和消息格式的任何变动及不稳定性都会影响C域;
(3) A域的消息和接口都是瞬时数据,两者由于时间差可能不一致,增加了C域处理的复杂度(例如:C域收到的消息是单据已创建,调用接口时查到该单据已完结);
(4) A域需要保证同步调用和消息通知的一致性,包括MQ不可用等情况发生时的容灾处理面对这些问题,我们希望应用事件驱动架构的特性来解耦子域,降低业务链路复杂度,构建稳定并向前兼容的事件契约,从而提升全域的稳定性。
(1)重新梳理全链路业务流和业务活动,建立统一的标准语言;
(2)定义标准的事件格式和通用基础字段;
(3) 各域定义包含完整业务语义、自闭包、多租户的领域事件;
(4) 开发并接入一套适应供应链业务特点的事件系统(NBF事件中心);
NBF[1] 是阿里巴巴供应链中台的基础技术团队打造的一个技术PaaS平台,全称是New-Retail Business Factory,她提供了微服务FaaS框架,低代码平台和中台基础设施等一系列的PaaS产品,旨在帮助业务伙伴快速复用和扩展中台能力,提升研发效能和对外的商业化输出。事件中心就是NBF系列技术产品中的一员。
本文首先介绍事件驱动架构的概念及适用场景,然后会介绍事件中心产品的设计和实现。
很多同学会将事件和消息混淆。在业务系统中,事件指的是领域事件,而消息可以是任意数据或数据片段。领域事件的特点包括:
(1)与服务接口一样有完整的schema,并保证schema向前兼容;
(2)是业务流程的一部分,由业务动作触发,包含了完整(或部分但有独立语义)的业务状态变化;
(3)事件消费者接收到事件后,相应修改自身的业务状态,并按需发出新的事件;消费者需要保证所有事件最终消费成功,否则会导致业务流程不完整;
(4)事件需要持久化保存并长期归档,方便业务同学查询、恢复中断的业务流程、重新发起业务流程等,也方便风控及财务分析同学做离线分析。
和很多架构名词类似,事件驱动架构并没有一个明确的定义和能力范围。Martin Fowler在2017年的文章[2] 中描述了与事件驱动架构相关的一些主要模式。在本文中,事件驱动架构的概念具象为由领域事件驱动的业务流技术架构。每一个领域事件都对应一个业务流中的具体活动(如采购单建单),而事件就是活动发生导致的结果(如采购单建单完成事件),事件内容就是活动导致的完整状态变化(如采购单+子单列表)。
在Fundamentals of Software Architecture[3] 以及Microservices Patterns[4]等书中描述了事件驱动架构的一些明显特点,我们总结为以下几项:
下面我们举几个例子来描述事件驱动架构的解耦和广播能力如何帮助解决现实工作中的问题:
解耦能力
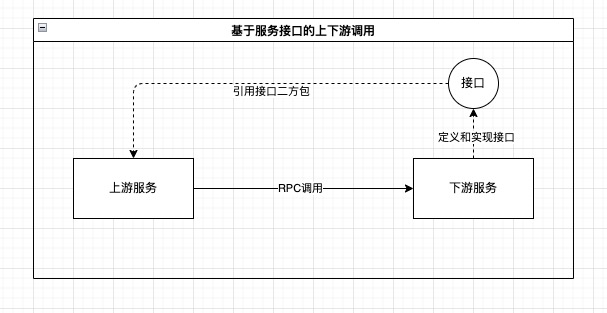
在基于请求/响应方式的服务化架构中,上游服务按照约定的RPC接口调用下游服务,这样有一个比较严重的问题:上游服务作为数据(例如业务单据)的生产者,强依赖了作为数据消费方的下游服务所定义的接口,导致上游服务自身无法沉淀接口和数据标准。
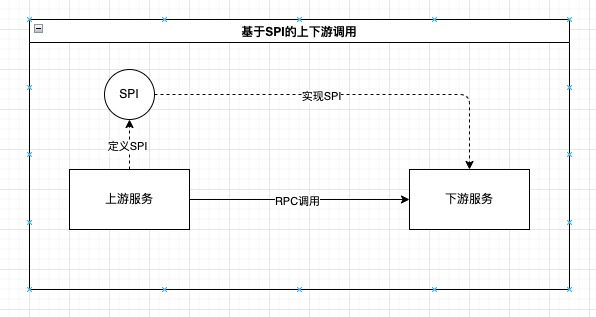
一种更合理的方案是依赖倒置:由上游服务定义SPI,下游服务实现SPI,这样,上游服务终于有机会沉淀出自身的接口和数据标准,不再需要适配各个下游服务的接口,而是由下游服务的开发者按照接口文档来做实现。但这种设计仍然无法解决运行时上游服务仍然依赖下游服务的问题,下游服务的可用性、一致性、幂等性能力会直接影响上游服务的相关指标及实现方式,需要上下游服务开发者一起对齐方案,在出问题时一起解决。
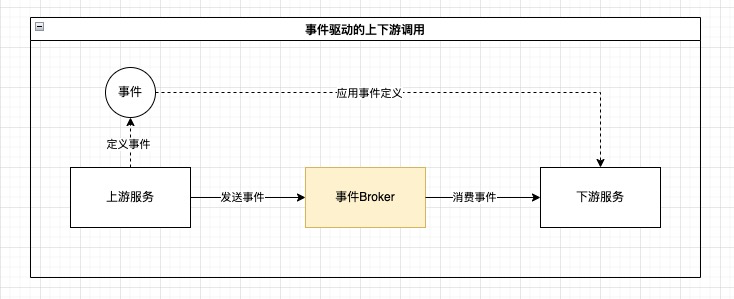
使用事件驱动设计可以实现契约定义和运行时的全面解耦:上游服务可以沉淀自己的事件契约,在运行时无论是上游服务还是下游服务都只依赖事件Broker,下游服务的可用性和一致性等问题由事件Broker来保障。
广播能力
在供应链中台这样复杂的微服务架构中,关键的上游服务往往有多个下游服务,上游服务一般需要顺序或并发调用所有的下游服务来完成一次完整的调用。
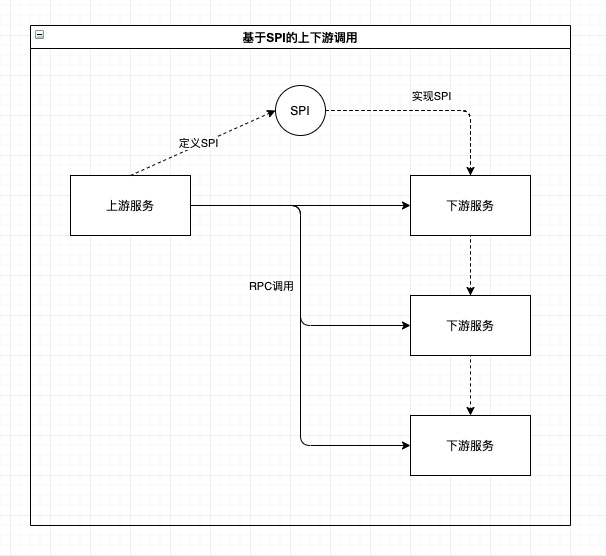
上游服务的开发者会面临多个难题:
而下游服务的开发者也有自己的问题:
使用事件驱动架构天然可以避免上述问题:
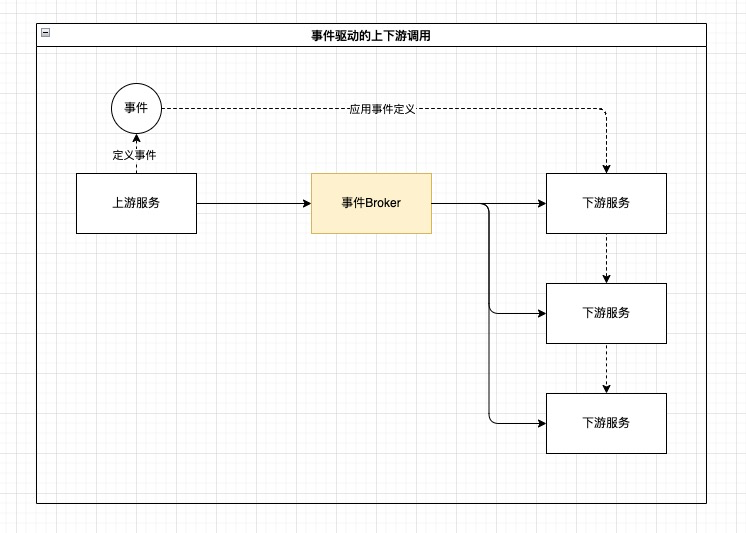
作为面向中台的事件中间件,事件中心集成了消息中间件MetaQ(RocketMQ),初始使用体感也与MQ很像,但事件中心有很多不同的功能设计:
(1)完善的权限控制;
(2) 支持事件契约定义以及运行时合法性校验;
(3) 支持大事件发送和消费(10MB或更高);
(4)支持长期的事件历史查询、事件索引查询(如单据编号、sku)、事件重投;
(5) 支持消费周期很长的事件(如需要几个月才能完结的入库单);
(6)所有事件及消费记录的完整归档;
(7)以OpenAPI的形式开放了事件查询、事件重投等运维态的功能,方便被其他系统集成。
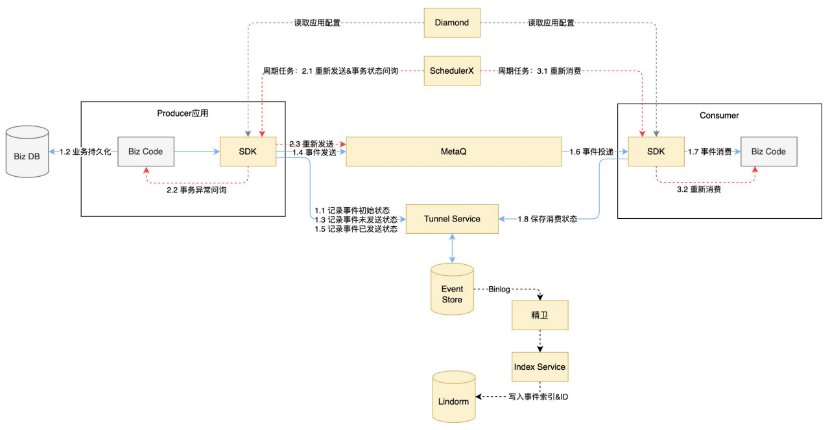
事件中心运行态主要由以下部分组成:
a) SDK:包含事件收发的主要逻辑,支持事务发送和普通发送,支持事件校验、压缩、本地备份;
b) Tunnel Service:一层很薄的数据库代理服务,支持按应用、事件、场景、IO维度的限流,支持数据库快速灵活扩容;
c) Index Service:事件索引服务,通过精卫(DataX)获取Binlog,解析为索引后写入索引表(Lindorm)。
a) Diamond(Nacos):包含应用相关的全部配置信息,如发送、订阅关系、事件定义、中间件配置等;
b) SchedulerX:调度SDK执行事件重新发送、重新消费、事务异常状态问询;
c) MetaQ:主要的事件收发管道;
d) TDDL(RDS):事件内容及消费记录存储;
e) 精卫:用于生成索引、计算延迟等异步处理逻辑;
f) Lindrom(serverless):用于存放事件外部索引,serverless模式支持按量付费和弹性扩容,性能比较稳定。
下图为简化的运行时架构图,图中蓝色线条表示事件的正常收发链路(事务发送),红色线条表示事件的异常处理链路。
事件结构
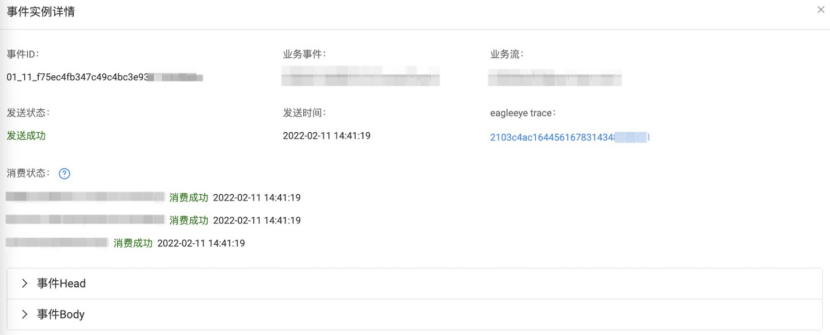
运行时的一条事件实例由三部分组成:
(1)事件ID:全局唯一,格式为“逻辑库编号_月内发送日期_uuid”,例如01_11_f75ec4fb347c49c4bc3e93xxxxxxxx,其中逻辑库编号用于逻辑库路由,日期用于事件清理;
(2) 事件Head:包含事件元信息,如trace信息、发送者信息、事件大小、MetaQ信息等,参考示例:
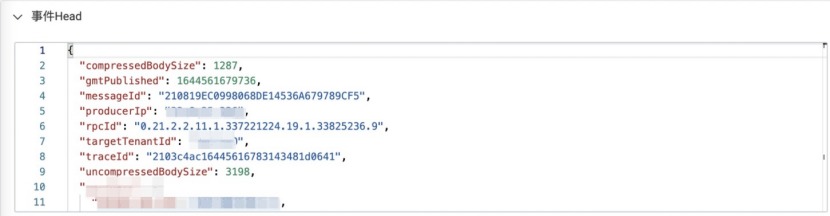
(3)事件Body:JSON格式,包含由用户已定义的事件内容,事件内容要符合事件定义契约,否则会被拒绝发送。
运行时的事件可能有多个消费方,每个消费方会产生一条消费记录,消费记录包含:
事件发送流程
事件中心支持事务发送和非事务发送两种模式,使用状态机驱动,API设计与MetaQ的API基本一致。以下以事务发送为例介绍发送流程,由于非事务发送的流程更简单,所以不再详细介绍。
1)事务发送状态机
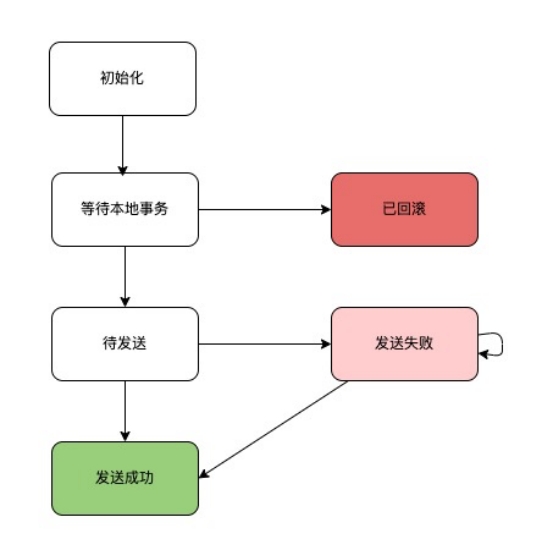
2)事务发送时序图
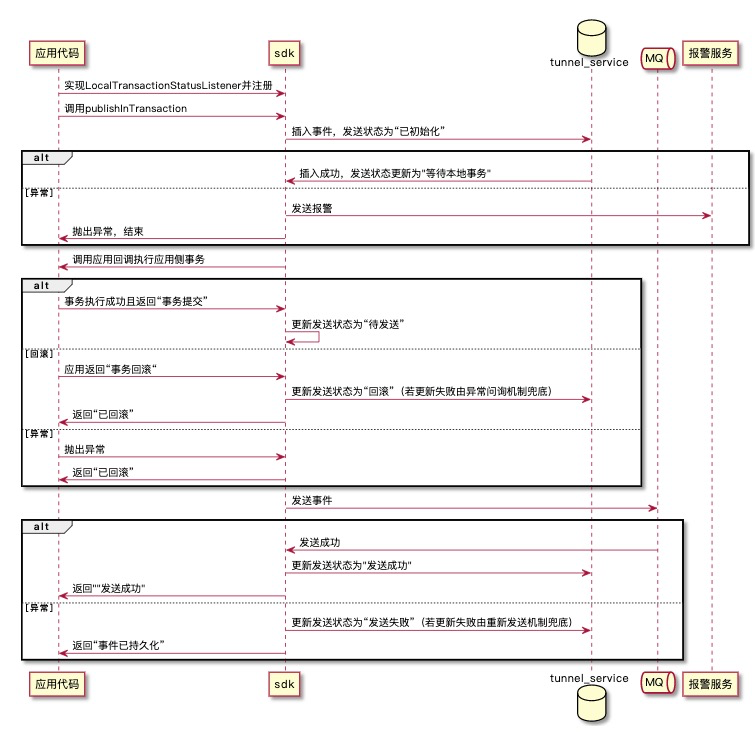
3)异常状态事务问询
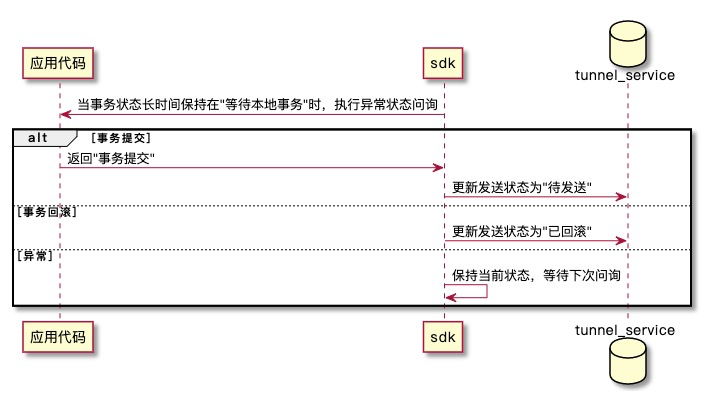
事件消费流程
事件消费流程也使用状态机驱动,API相比MetaQ有一些不同:
(1)不需要再调用subscribe topic;
(2)新增消费过滤器EventFilter,支持按照租户、业务流、事件维度做过滤;
(3)支持不同的事件使用不同的Listener消费;
1)事件消费状态机
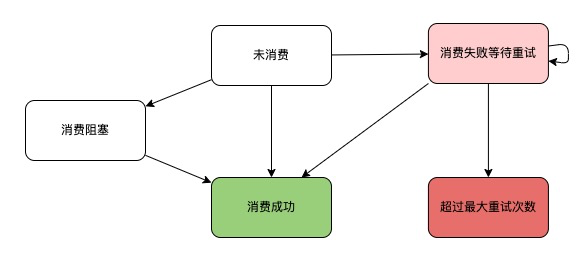
2)重试周期
事件进入消费失败状态后,事件中心会周期调用用户Listener重新消费,消费周期以5s起始指数增加,最多重试15次,最大为5 * 214 = 81920秒(约22小时)。
3)事件消费时序图

数据表
事件中心使用了32分库的TDDL,按照HASH(事件ID)做分库,每个库上有以下几张表:
(1)事件主表,包含发送者信息、事件信息以及普通事件的事件体;
(2) 事件消费记录主表,包含消费者信息、消费状态以及重新消费信息,与事件主表通过事件ID关联;
(3)大事件主表,包含大事件体,与事件主表通过事件ID关联;
(4) 事件天表,表结构与事件主表相同,存放消费完毕的事件;
(5)消费记录天表;
(6)大事件天表;
事件生命周期
(1)新写入的事件和消费记录会进入主表;
(2)当事件写入超过1天,且事件的所有消费方都消费成功后,事件及所有消费记录会从主表移动到天表中;
(3)当事件某个消费方需要重新消费之前消费成功的事件时,事件及所有消费记录会从天表移回到主表中;
(4) 每天的某个时间,事件清理服务会将7天前的那张天表清空,例如今天是2月11号,那么就会清空2月4号的所有天表。
事件发送历史列表、事件索引查询和事件重投是事件中心运维平台的主要功能。其中索引查询功能的查询速度快、查询结果准确,用户反馈一直比较好。
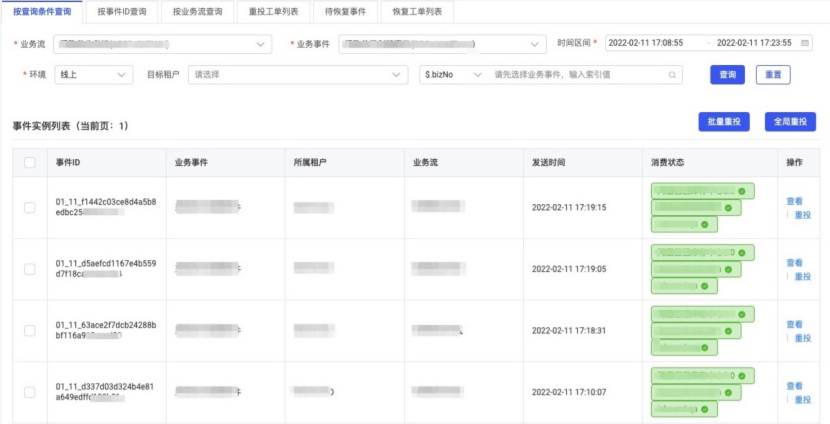
索引配置
用户在修改事件定义时,可以为其中任意基础类型字段配置为“查询字段”,事件中心会在运行时解析该字段的值,并创建索引;一个事件中的每个查询字段都会对应一条索引;即使没有配置查询字段,也会生成一条包含时间戳的索引,用于已发送事件的排序和分页。
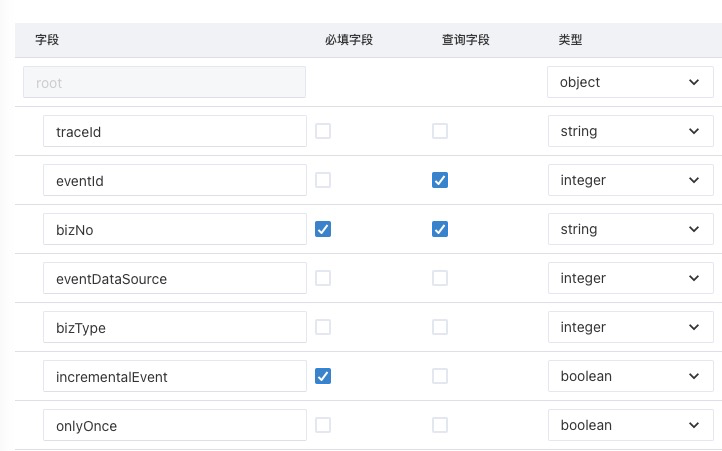
索引结构
事件中心的索引为KV结构,使用Lindorm的宽表存储,按使用场景分为两种类型:
(1)不包含查询字段的索引;
(2)Key格式为 HASH(租户id_事件code)_env_发送时间差值_事件ID;
(3)Value为事件ID、事件头;
(4)包含查询字段的索引;
(5)Key格式为 HASH(租户id_事件Code_字段路径_索引值)_env_发送时间差值_事件ID;
(6) Value为事件ID、事件头;
其中
(1)发送时间差值 = Long.MAX_VALUE - 发送时间毫秒数,用于按发送时间倒序展示;
(2)字段路径是json path格式,例如 $.bizNo;
查询性能
通过目前事件中心运维平台99%的查询都可以在毫秒级别返回结果,Lindorm索引行数在十亿级别。
本文介绍了事件驱动架构在供应链执行链路的应用背景和实践过程,并介绍了NBF事件中心产品的设计和部分实现。目前事件中心每日事件发送量峰值在千万级别,平稳度过了双11、双12、年货节等流量高峰。


科技有限公司")
科技有限公司")
 云计算走到十字路口,自动化将成为行业的新常态
云计算走到十字路口,自动化将成为行业的新常态
 社交应用会是罗永浩的下一个“翻身仗”么?
社交应用会是罗永浩的下一个“翻身仗”么?
 新兴技术趋势:从物联网到边缘计算
新兴技术趋势:从物联网到边缘计算
 “死线”临近你还会不会继续用Windows7?
“死线”临近你还会不会继续用Windows7?
 云自动化简化 IT 运营的七大优势
云自动化简化 IT 运营的七大优势
