在不稳定的2020年之后,对新的一年有何看法?
关于2020年已经说了太多话了。这么多耻辱,不幸,悲伤……是的,我们都知道!我们在一起吗?
但是,围绕我们的所有这些耻辱和不幸并没有阻止巨大的研究和进步。伟大的成就并没有道歉,"抱歉,那我要等2021年……"。太好了,世界在不断发展。

数据科学正变得如此成熟,以至于我回顾了以前的回顾性文章(2019、2020),我觉得我们需要比以往任何时候都更加开始讨论复杂而严肃的话题。我是那个变老吗?
当然,像Tensorflow甚至sklearn这样的核心技术都在发展,但是这些是现在的主要问题吗?我相信不是。
在这篇文章中,我将集中讨论两个主要主题。在不破坏太多的情况下,它们是:
有兴趣吗我们走吧。
1. 事实和共同点
不能说技术进步不好。它们是我们可以用于我们想像的任何工具的工具,无论好坏。可以找到广泛的例子,其中技术始于军事应用,并成功地应用于民用技术(我喜欢这个清单)。但是,有很多我们首先不希望在军事应用中使用的数据科学工具……

我为什么要谈论它?让我呆一会儿,继续前进……今年,我们(至少)发生了两个非常特殊的事件-美国大选和COVID-19。我开始注意到侧面(观点/立场/陈述)变得比以往更加两极化。我个人和朋友们进行了一些艰难的讨论。我开始感到我们缺少一些东西–需要一个共同点。基本上,我们之间可以达成共识的是事实?看起来很简单,但如今却如此复杂。
人们开始依靠自己的新闻频道(某些情况下,社交媒体供稿),每个新闻频道都有自己的观点和针对性的建议,而没有过滤掉对广告内容的正确或错误的判断。我们可以进行富有成效(健康)的讨论的共同基础开始消失。对其他来源不信任。
这与数据科学有何关系?它涉及最被低估的领域之一,人们通常要么做出粗略的假设,要么独自忽略。称为数据来源(Wiki定义)。
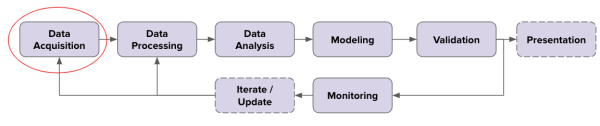
我希望在2021年,有关数据来源的讨论会增加。
数据从哪里来?我们可以相信吗?它是否包含代表性数据?在部署模型之前,我们应该对数据有什么了解吗?我们怎么知道将来它将继续成为可靠的来源?
我真诚的认为,我们还没有认真对待数据来源评估。有很多不好的例子,使用未经检查的数据会导致更多的错误信息或歧视。
现在,回到技术进步,并与数据来源联系起来,今年,我们看到了通用对抗网络(GAN)的一些令人印象深刻的应用。例如,伊丽莎白女王的Deepfake通过第4频道到达大众(youtube视频)。大家的反应不一,但我可以看到,该视频的目的是将信任讨论摆到桌面上。我们可以相信自己的眼睛吗?从现在起,我们可能需要变得更加怀疑。
对Deepfake的无节制使用会破坏公众对报纸和电视的信任。数据来源必须明确,我们需要找到一种方法来确定什么可以被信任。
2. 我们都可以做数据科学吗?
2020年为我们带来了数据科学应用程序的许多发展,它使用了最近几年(某种)可用的技术,但现在使用了更多的计算能力。两个例子:
几年前,我们可以看到数据科学的发展来自单身人士或小型创业公司。如今,由于我们处于一个阶段,我们需要大量的计算资源来训练某些模型,因此这变得更加困难。例如,Deepmind提到Alphafold,
…使用大约16个TPUv3(即128个TPUv3内核或大约相当于100-200个GPU)运行了几周…
关于OpenAI的GPT-3,
使用Tesla V100云实例训练GPT-3的成本将超过460万美元。
这是否意味着Data Science / AI的民主程度降低了?群众仍然可以使用吗?
一种解决方案是对需要较少数据才能取得良好结果的模型的开发进行更深入的研究。我们一直专注于模型的准确性/ ROC / RMSE / etc。在最近几年中,并没有太多地影响它们的效率。资源不是无限的,特别是对于业余数据科学家来说,他们也希望在不依赖大型基础架构的情况下对应用程序有所了解(=高成本,=第三方)。
另一个解决方案可以是所有人都可以使用的开源预训练模型。但是,如果所有者不完全清楚如何创建模型以及使用哪些数据,则可能属于上述问题(数据来源)。尽管如此,只要公众具有适当的透明度和开放性,他们可以参与创建这些经过预先训练的模型,我们也许可以达成共识。


科技有限公司")
科技有限公司")
 使用哪种编程语言的开发人员最幸福?
使用哪种编程语言的开发人员最幸福?
 边缘计算:云的末日到了吗?
边缘计算:云的末日到了吗?
 云计算与边缘计算
云计算与边缘计算
 边缘计算:五个潜在陷阱
边缘计算:五个潜在陷阱
 2021去中心云计算行业概览
2021去中心云计算行业概览
